서론: x86 아키텍처의 종말과 시스템 온 칩(SoC)의 도래
2020년, 애플(Apple)이 인텔(Intel)의 x86 프로세서를 버리고 자체 설계한 애플 실리콘(Apple Silicon) M1 칩을 발표했을 때, 이는 단순히 부품 공급사를 변경하는 차원이 아니었다. 이는 지난 수십 년간 PC 시장을 지배해 온 CISC(Complex Instruction Set Computer) 기반의 컴퓨팅 패러다임이 모바일 태생의 RISC(Reduced Instruction Set Computer) 기반 아키텍처로 전환되는 역사적인 분기점이었다. 애플 실리콘은 M1을 시작으로 M2, M3, 그리고 최신 M4에 이르기까지 비약적인 '전력 대비 성능비(Performance per Watt)'를 증명하며 반도체 설계의 표준을 재정립하고 있다. 본고에서는 애플 실리콘의 압도적인 성능을 가능케 한 SoC(System on Chip) 설계 방식, ARM 아키텍처의 특성, 그리고 가장 핵심적인 기술인 **통합 메모리 구조(Unified Memory Architecture)**의 작동 원리를 공학적 관점에서 면밀히 분석한다.
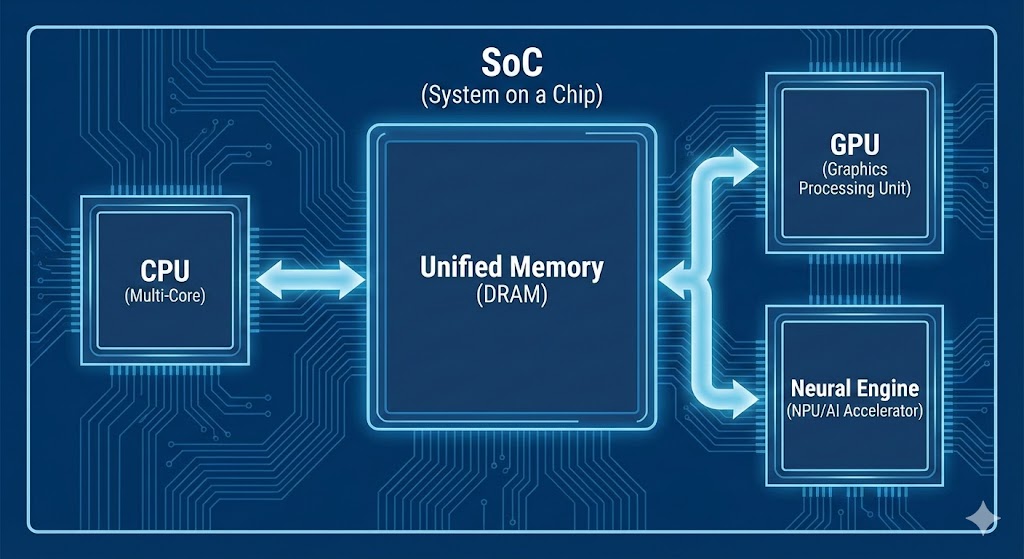
1. 애플 실리콘의 정의와 기초 원리: RISC 기반의 SoC 설계
애플 실리콘의 가장 큰 구조적 특징은 시스템 온 칩(SoC) 설계를 채택했다는 점이다. 기존의 전통적인 PC 아키텍처는 CPU(중앙처리장치), GPU(그래픽처리장치), RAM(메모리), I/O 컨트롤러가 마더보드 상에 물리적으로 분리되어 존재했다. 이 경우 각 부품 간 데이터를 주고받는 과정에서 물리적 거리에 따른 지연(Latency)과 전력 소모가 필연적으로 발생한다. 그러나 애플 실리콘은 이 모든 핵심 구성 요소를 단 하나의 실리콘 다이(Die) 위에 통합하였다. 이는 데이터의 이동 경로를 극단적으로 단축시켜 처리 속도를 높이고 전력 효율을 극대화하는 결과를 낳았다.
또한, 애플 실리콘은 ARM 아키텍처를 기반으로 설계되었다. 인텔의 x86 방식이 복잡하고 다양한 명령어를 처리하기 위해 거대한 회로를 구성하는 CISC 방식이라면, ARM 기반의 애플 실리콘은 명령어를 단순화하여 처리 효율을 높이는 RISC 방식을 취한다. 과거 RISC는 단순한 연산에는 유리하지만 고성능 컴퓨팅에는 부적합하다는 편견이 있었으나, 애플은 명령어 파이프라인 최적화와 트랜지스터 집적도 향상을 통해 이러한 한계를 기술적으로 극복했다. 즉, 애플 실리콘은 모바일 칩셋의 낮은 전력 소모 특성을 유지하면서도 데스크톱 수준의 강력한 연산 능력을 구현한 하이브리드 기술의 정점이라 할 수 있다.
2. 심층 분석: 통합 메모리 구조(UMA)와 초미세 공정의 메커니즘
애플 실리콘이 기존 프로세서와 차별화되는 가장 결정적인 기술은 **통합 메모리 구조(Unified Memory Architecture, UMA)**이다. 일반적인 PC 시스템에서는 CPU와 GPU가 각각 별도의 메모리(DRAM, VRAM)를 사용한다. 따라서 CPU가 처리한 데이터를 GPU가 받아 그래픽 작업을 수행하려면, 데이터를 복사(Copy)하여 이동시키는 과정이 필요하다. 이 과정에서 병목 현상이 발생하고 시스템 자원이 낭비된다.
반면, 애플 실리콘의 UMA는 CPU, GPU, 뉴럴 엔진(Neural Engine) 등 칩 내의 모든 프로세서가 **단일한 고대역폭 메모리 풀(Memory Pool)**에 접근할 수 있도록 설계되었다. 이는 데이터를 복사할 필요 없이 메모리 주소 포인터만 공유하면 되므로, 데이터 처리의 지연 시간을 획기적으로 줄여준다. 예를 들어, M3 칩의 경우 최대 128GB의 용량과 400GB/s에 달하는 메모리 대역폭을 프로세서 간 경계 없이 유동적으로 할당할 수 있다. 이는 고해상도 렌더링이나 거대 언어 모델(LLM) 구동 시, 별도의 VRAM 용량 제한 없이 시스템 전체 메모리를 그래픽 메모리처럼 활용할 수 있게 하여 압도적인 퍼포먼스를 제공한다.
여기에 더해 TSMC의 3나노미터(nm) 공정 기술은 물리적 한계를 돌파하는 데 기여했다. 회로 선폭을 원자 단위 수준으로 줄임으로써, 손톱만한 크기의 칩 안에 수백억 개의 트랜지스터(M3 Max 기준 920억 개)를 집적할 수 있게 되었다. 트랜지스터 간 거리가 좁아지면 전자의 이동 거리가 짧아져 속도는 빨라지고 발열은 감소한다. 이러한 초미세 공정 기술은 애플 실리콘이 높은 클럭 속도를 유지하면서도 팬리스(Fan-less) 노트북인 맥북 에어와 같은 폼팩터를 가능하게 만드는 하드웨어적 기반이 된다.
3. 경쟁 기술 비교 및 응용: 빅-리틀(big.LITTLE) 구조의 효율성
애플 실리콘의 또 다른 기술적 우위는 **빅-리틀(big.LITTLE)**이라 불리는 비대칭 멀티코어 프로세싱 구조의 고도화에 있다. 이는 고성능을 담당하는 **'성능 코어(Performance Core)'**와 저전력을 담당하는 **'효율 코어(Efficiency Core)'**를 결합하여 작업의 부하에 따라 유기적으로 코어를 할당하는 기술이다.
기존 x86 프로세서들도 최근 하이브리드 아키텍처를 도입하고 있으나, 애플의 전력 관리 컨트롤러(Power Management Controller)는 운영체제(macOS)와 하드웨어가 완벽하게 결합되어 있어 스케줄링의 정교함에서 차이를 보인다. 예를 들어, 사용자가 4K 영상을 렌더링하는 동시에 웹 서핑을 할 때, 렌더링 작업은 성능 코어에 할당하여 빠르게 처리하고, 백그라운드의 웹 서핑이나 음악 재생은 효율 코어에 할당한다. 효율 코어는 성능 코어 대비 약 10분의 1 수준의 전력만으로 작동하므로, 전체 시스템의 배터리 수명을 비약적으로 늘릴 수 있다.
이러한 기술적 특성은 실생활 응용 분야에서 명확한 이점을 제공한다. 특히 영상 편집, 3D 모델링, 코드 컴파일과 같은 워크스테이션급 작업을 전원 연결 없이 배터리만으로도 성능 저하(Throttling) 없이 수행할 수 있다는 점은 기존 x86 기반 노트북이 제공하지 못했던 사용자 경험이다. 또한, 칩 내부에 내장된 **뉴럴 엔진(Neural Engine)**은 머신러닝 연산에 특화된 가속기로, 이미지 처리나 음성 인식과 같은 AI 작업을 CPU 부하 없이 독립적으로 처리하여 시스템의 전반적인 반응 속도를 향상시킨다.
결론: 개인용 컴퓨팅 아키텍처의 완성형
애플 실리콘은 단순한 CPU 교체를 넘어, 컴퓨터 구조학(Computer Architecture) 관점에서 메모리 계층 구조와 명령어 처리 방식을 재해석한 결과물이다. SoC 설계를 통한 지연 시간 최소화, UMA를 통한 데이터 처리 효율성 극대화, 그리고 미세 공정과 아키텍처 최적화를 통한 전력 효율 달성은 향후 반도체 산업이 나아가야 할 방향을 제시하고 있다. 현재 퀄컴(Qualcomm)의 스냅드래곤 X 엘리트 등 윈도우 진영에서도 ARM 기반 칩셋 개발에 박차를 가하고 있는 현상은 애플 실리콘이 증명한 기술적 방향성이 옳았음을 방증한다. 앞으로 등장할 M4, M5 칩셋은 더욱 고도화된 AI 연산 능력과 미세 공정을 통해 모바일과 데스크톱의 경계를 완전히 허무는 '완성형 컴퓨팅'을 구현할 것으로 전망된다.
'IT 정보&팁' 카테고리의 다른 글
| [기술분석] 아이패드 칩셋과 디스플레이의 계급론: M4, M3, 그리고 A16의 구조적 차이 (0) | 2026.01.30 |
|---|---|
| 2026 애플 신학기 프로모션: 아이패드 대 맥북, 하드웨어 아키텍처 및 OS 환경에 따른 기술적 비교 분석 (0) | 2026.01.30 |
| 애플 실리콘 M5와 M4 Pro/Max의 성능 역설: 세대 교체와 체급 차이의 기술적 분석 (0) | 2026.01.29 |
| 애플 실리콘 M4와 차세대 M5 칩셋 아키텍처 심층 분석: 공정 미세화와 성능의 상관관계 (1) | 2026.01.29 |
| 애플 실리콘 M5 vs 최신 인텔 코어 울트라: 아키텍처 차이와 성능 효율성 심층 분석 (0) | 2026.01.29 |



